個人的な創作物の中で,「画面のスクリーンショットを取ってその中の文字をOCRで読み取る」ということをしたかったので調べたところ,Tesseract OCRというOCRツールがあることを知りました.しかもPythonライブラリであるpyocrを使うことでPythonからも扱うことができるということで早速使ってみました.
そのインストール手順のメモになります.
OCRとは
OCR(Optical Character Recognition/Reader、オーシーアール、光学的文字認識)とは、手書きや印刷された文字を、イメージスキャナやデジタルカメラによって読みとり、コンピュータが利用できるデジタルの文字コードに変換する技術です。
私の用途的に説明すると,画像データ中の文字をテキストに起こしてくれる技術ということです.
Tesseract OCRとは
OCRツールの一種で,以下の特徴があります.
- Githubで公開されているオープンソースのOCRツール
- 様々な言語の訓練データが公開されている(日本語もあるよ)
- Pythonからも使える
おそらくPythonに限らずにTesseract OCR(以下,Tesseract)を使えるようなライブラリはあると思います.
Tesseract + PythonでOCRを行う
以下の順で説明していきます.
- 環境
- Tesseractのインストール
- Tesseractを使ってみる
- pyocrのインストールしてPythonで使う
環境
- xUbuntu 16.04
- Python2.7
Tesseractのインストール
今回は確実に最新版をインストールするために,ソースからビルドしてみます.と言っても,Githubに公開されている手順通りにやっていくだけです.また,Githubの手順では自身でトレーニングを行うためのトレーニングツールが必要な人向けの手順も書いてありますが,私は取り急ぎOCRが使えれば良かったため,本記事では飛ばしたいと思います.
まずは依存関係をインストールします.
|
1 2 3 4 5 6 7 8 |
$ sudo apt-get install g++ # or clang++ (presumably) $ sudo apt-get install autoconf automake libtool $ sudo apt-get install autoconf-archive $ sudo apt-get install pkg-config $ sudo apt-get install libpng12-dev $ sudo apt-get install libjpeg8-dev $ sudo apt-get install libtiff5-dev $ sudo apt-get install zlib1g-dev |
次にLeptonicaという画像ライブラリをインストールします.apt-getでも入れられるのですが,Tesseractの最新版では1.74.0が必要になりますので,Leptonicaも最新版をソースからビルドします.ソースはこちらから最新版を得られます.
|
1 2 3 4 5 6 |
$ wget http://www.leptonica.com/source/leptonica-1.74.1.tar.gz $ tar xvzf leptonica-1.74.1.tar.gz $ cd leptonica-1.74.1 $ ./configure $ make $ sudo make install |
さて,ここまででTesseractをビルドする準備ができました.以下のようにしてビルドします.
|
1 2 3 4 5 6 |
$ git clone https://github.com/tesseract-ocr/tesseract.git $ cd tesseract $ ./autogen.sh $ ./configure $ make $ sudo make install |
これでTesseractが入りました.
Tesseractは/usr/local/share/配下の訓練データを参照してOCRを行います.Tesseractインストール直後は訓練データがありませんので,こちらから興味のある言語の訓練データをダウンロードしましょう.私は英語と日本語が使いたいので,eng.traineddataとjpn.traineddataをダウンロードし,/usr/local/share/配下に置きました.
ここまで行うと,コマンドラインからTesseractを使用できるようになります.適当なデータで試してみましょう.私はこのようなデータを使いました.

コマンドは以下です.
|
1 |
$ tesseract my_test.png result |
my_test.pngが上の画像ファイル,resultは出力ファイル名です.自動的にresult.txtとなります.結果は以下です.
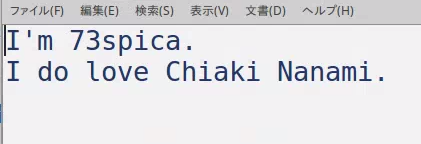
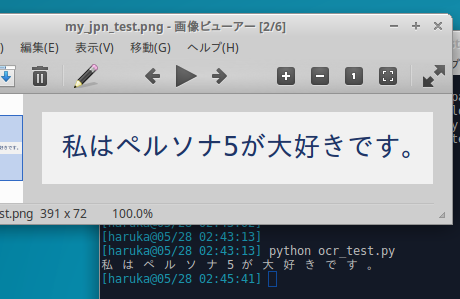
テスト用の画像作るときも結果を参照する時も同じエディタを使っていてわかりにくいかもですが,ちゃんと読み取れています.
同様に日本語でもやってみます.

コマンドは以下です.
|
1 |
$ tesseract my_jpn_test.png jpn_result.png -l jpn |
-l オプションで言語を指定します.結果は以下です.

思ったよりきちんと読み取れています.
(参考にした記事では,複雑な文章等を扱うとはちゃめちゃな結果になるとありました.そのような場合は自分で訓練データを作ると良いそうです.公開されている訓練データも改善されているのかもしれませんね.)
追記)
いくつかの日本語の文章を試してみましたが,やはり英語に比べると精度が低いようです.しかし画像を拡大したりするだけで精度が変わるので,画像中の文字が細かい場合や画像自体が小さい場合は画像を加工すればだいぶ読みやすくなります.
pyocrをインストールしてPythonで使う
では,TesseractをPythonから使ってみます.まずはpyocrをインストール.
|
1 |
$ sudo pip install pyocr |
これでPythonでTesseractを扱えます.
(参考にした記事ではTesseractをソースからビルドした場合,とあるひと手間必要とのことでしたが,現在は修正されてひと手間がいらないみたいです.)
では,簡単なテストコードを書いてみます.先ほどの日本語のデータでテストしてみます.
|
1 2 3 4 5 6 7 8 9 |
import pyocr import pyocr.builders from PIL import Image tools = pyocr.get_available_tools() tool = tools[0] res = tool.image_to_string(Image.open("./my_jpn_test.png"), lang="jpn", builder=pyocr.builders.TextBuilder(tesseract_leyout=6)) print res |
|
1 2 |
$ python ocr_test.py 私 は ペ ル ソ ナ 5 が 大 好 き で す 。 |
このように,コマンドラインから実行した時と同様の結果なります.
ソースコード中のimage_to_stringというメソッドの引数にbuilderというものがあります.さらに中を見ると,pyocrのTextBuilderの中でterreract_layoutというパラメータに6を指定しています.これはTerreractコマンドの-psmオプションにあたるもので,-psm 6 と同義になります.このオプションはpage seg modeの略で,画像をどのように(どんな画像だと思って)読み取るかというものです.以下が各値の対応です(参考).
|
1 2 3 4 5 6 7 8 9 10 11 12 |
pagesegmode values are: 0 = Orientation and script detection (OSD) only. 1 = Automatic page segmentation with OSD. 2 = Automatic page segmentation, but no OSD, or OCR 3 = Fully automatic page segmentation, but no OSD. (Default) 4 = Assume a single column of text of variable sizes. 5 = Assume a single uniform block of vertically aligned text. 6 = Assume a single uniform block of text. 7 = Treat the image as a single text line. 8 = Treat the image as a single word. 9 = Treat the image as a single word in a circle. 10 = Treat the image as a single character. |
例えば,縦書きのテキストの画像を読み取る場合,virtically aligned textなので5を指定します.精度良く読み取るためには,このようなオプションの値もしっかり設定する必要があるでしょう.
まとめ
Tesseract OCRをxUbuntuにインストールしてコマンドラインで簡単なOCRを行いました.今回はソースからビルドする方法を紹介しました.
また,pyocrをインストールしてPythonからTesseract OCRを使用しました.