最近,ハッシュの一種であるSHA-1について,米Googleが初めて衝突に成功させたということが話題になりました.その衝突ハッシュを使った衝突例として,SHA-1の一致する二つのPDFを作成していました.
その方法について説明されている資料があったので自分でもSHA-1を衝突させたPDFを作成してみました.その方法について書こうと思います.
はじめに
本記事はGoogleの発見したNear-collision Pairを用いて二つの異なるPDFのSHA-1を衝突させる(SHA-1の異なる二つのPDFを作る)手法を解説した記事ですが,以下の点について知識が不足している部分があります.
- PDFのフォーマット
この点については,衝突の原理に直接かかわらないので細かく調べていませんがご了承ください.そしてもし詳しい方がいたらその点ご指摘いただけたらありがたいです.
SHA-1? ハッシュ関数? 衝突?
まずハッシュ関数についてから書こうと思ったら,あれも書きたい,これも書かなきゃ,となって本命のSHA-1衝突の話題がかすれてしまいそうだったので,これは機会があれば別記事に書きたいと思います .
簡単に説明しますと,
- SHA-1は一方向性関数で,あるデータに対して一意の数列 (ハッシュ) が得られる
- 同じく一方向性関数であるMD5は,異なる二つのデータから同様のハッシュが得られることが知られている
- SHA-1も危ないと昔から言われていたが,とうとうGoogleが衝突例を発見した
という感じです.
GoogleがやったPDF衝突方法
Googleが実現した衝突方法は以下の通りです.
- PDFとJPGの機能を用いた衝突
- 多量のリソースを使った大規模な演算で,あるヘッダPについてSHA-1( P | M1 ) = SHA-1( P | M2 )となる P, M1 , M2を見つけた
- SHA-1の計算の性質上,( P | M1 )と( P | M2 )の時点で衝突が発生すれば,あるデータSについて( P | M1 | S ) と ( P | M2 | S )のハッシュも衝突する
Googleがこのような( P | M1 )と( P | M2 )をIdentifical-prefix Collision Attackという手法で発見しました.Googleが発見してくれたおかげで,僕らはSの部分をちょっと細工するだけで簡単に衝突PDFを作ることができます(このM1とM2という同じSHA-1を取るペアはNear-collision Pairと名付けられています).Googleの衝突PDFは,開くと違う画像が表示されるのに同一のSHA-1ハッシュが得られるという代物なのですが,実はこの2種類の画像はどちらのPDFにも含まれています.詳細は後程説明します.
原理については私が参考にした資料であるGoogleのSHA-1の話 (サイボウズさんの社内勉強会用のスライド)を参照するのが参考になると思います.この記事では自分が実際に行ったSHA-1衝突PDF作成手順について図を用いて説明したいと思います.
衝突手順
用意するもの
衝突原理の理解のために僕が使ったものです.
- 既存の衝突PDF1 ( shattered-1.pdf )
- 既存の衝突PDF2 ( shattered-2.pdf )
- 衝突PDFから,表示されるJPGを抽出するスクリプト ( extract-jpeg.py )
- バイナリエディタ ( stirlingとか )
まず,既存の衝突PDFファイル二つです.こちらのサイトから入手できます.Attack ProofのとこのPDF1 | PDF2 という部分をクリックすればそれぞれダウンロードできます.開いてみると二つの異なるJPGが表示される全く別のPDFファイルであるにも関わらず,SHA-1の値が同じになっていることが分かります.
|
1 2 3 4 5 6 7 |
$ md5sum shattered-* ee4aa52b139d925f8d8884402b0a750c *shattered-1.pdf 5bd9d8cabc46041579a311230539b8d1 *shattered-2.pdf $ sha1sum shattered-* 38762cf7f55934b34d179ae6a4c80cadccbb7f0a *shattered-1.pdf 38762cf7f55934b34d179ae6a4c80cadccbb7f0a *shattered-2.pdf |
次に,それぞれのPDFから,表示されている画像を抽出するスクリプトを入手します.こちらのGithubで公開されてます.先ほども申し上げた通り,衝突PDFで表示されている2種類の画像は,どちらのPDFにも含まれているにも関わらず,互いに違う方のみが表示されます.上記のスクリプトは,そのうちの表示されている方のみ抽出できるスクリプトであるということです.これを使って既存の衝突PDFから画像を抽出して構造を見比べたり,自分で作った衝突PDFに使ってみてきちんと画像が抽出されるかを確認したりできます.例えば,自分で作ったPDFに対して使ったらきちんと画像を抽出できるにも関わらずPDFが表示されない時は,上手く相互を参照するようにはできているのにどこか別の要因で表示されていないということになります.とりあえずやってみればわかります!
衝突PDFの構造の理解・自作をするためにはバイナリエディタが必要になります.これでバイナリを見ながら値を細工していきます.細工と言ってもやることが分かってしまえば簡単です.
既存の衝突PDFの構造(衝突原理)の概要を把握する
まずは衝突PDFをリーダーで見てみます.赤と青の別の画像が表示されています.
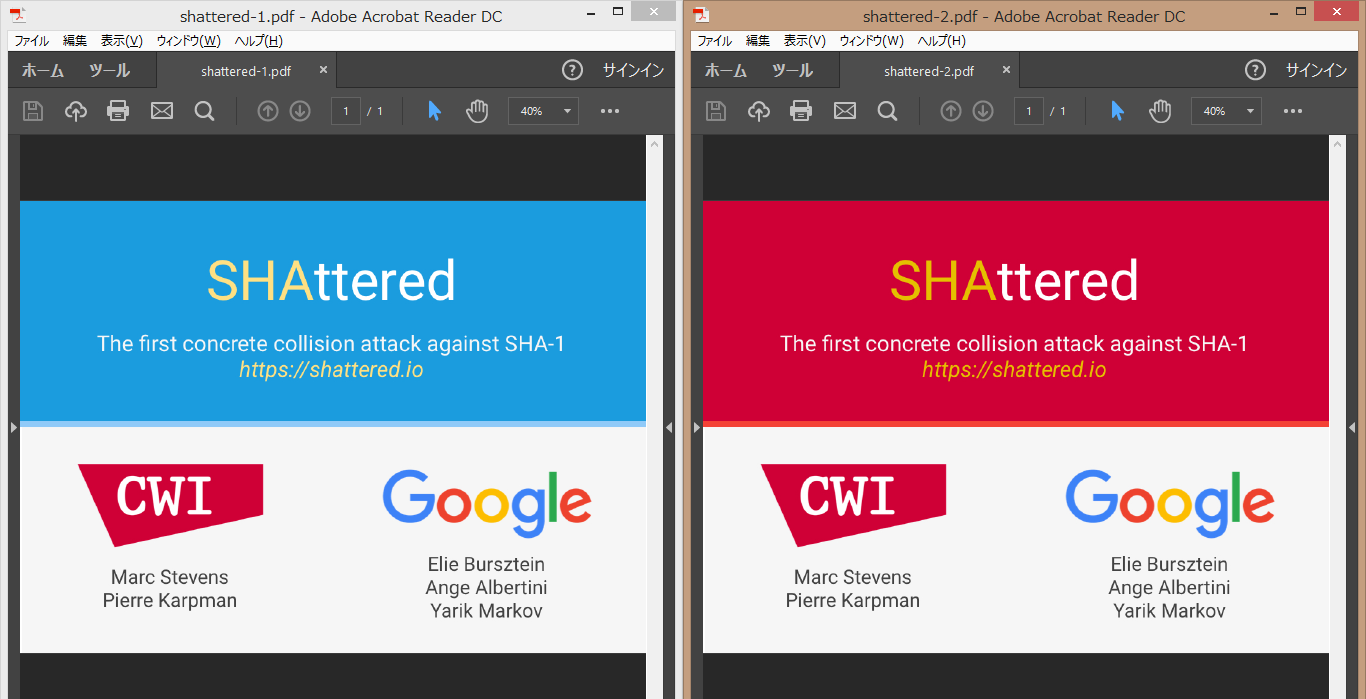
次はこれらの16進バイナリを見てみます.サイボウズの資料によりますと,先頭320バイトの部分で衝突が起きていてそれ以降が同じ値ならずっと衝突し続けるとのことです.なので,まずはコマンドで先頭320バイトのSHA-1を見てみます.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
// 320バイトではどちらのSHA-1も衝突している $ dd bs=1 count=320 < shattered-1.pdf | sha1sum ~~~ f92d74e3874587aaf443d1db961d4e26dde13e9c *- $ dd bs=1 count=320 < shattered-2.pdf | sha1sum ~~~ f92d74e3874587aaf443d1db961d4e26dde13e9c *- // 256バイトの段階では衝突していない $ dd bs=1 count=256 < shattered-1.pdf | sha1sum ~~~ 5b72b916c85d1980f8ac6846fad79b9b70ea7f85 *- $ dd bs=1 count=256 < shattered-2.pdf | sha1sum ~~~ b93c8b91b1822d1f23d0b67c12e97ed0208b491e *- |
じゃあこの320バイトってどうなってるの?ってなるので,早速バイナリエディタで見てみます.
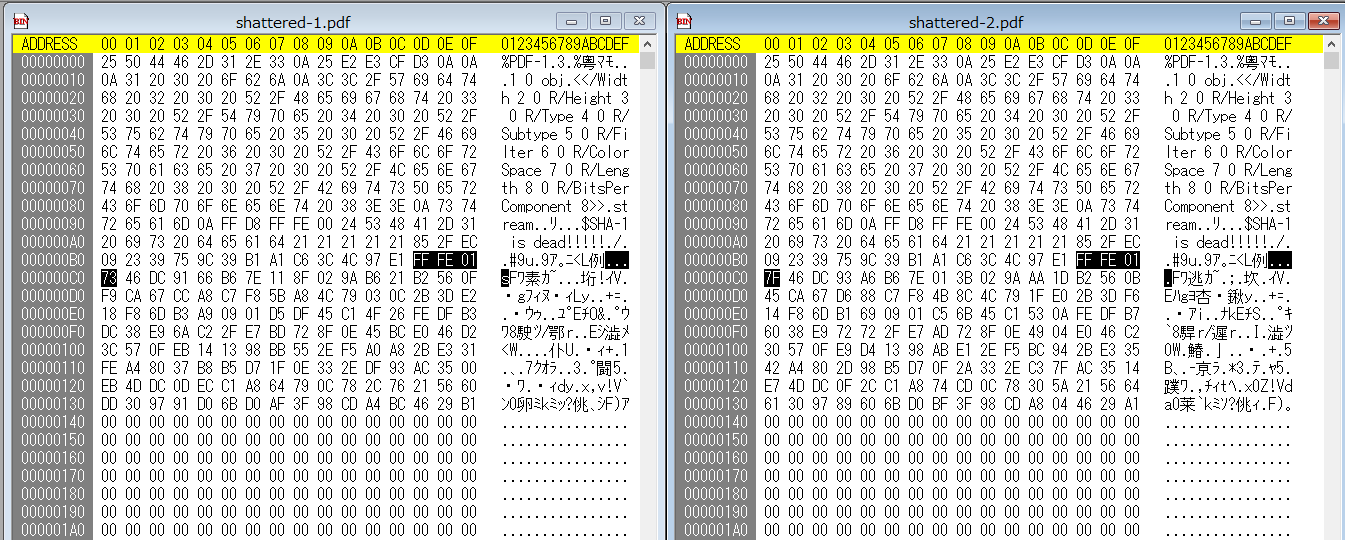
こんな感じです.この画像は320バイトの最後の方が見えてないのですが,320バイト目までずっと0が続くだけなので良しとします.大事なのは選択している部分です.それぞれ以下のようになっています.
- FF FE 01 73:shattered-1.pdf
- FF FE 01 7F:shattered-2.pdf
このバイナリが何を表しているかというと,実はJPGファイル内にあるコメント部分を表しています.「何で突然JPG? PDFじゃないの?」となりますが,実はそれより前にあるFF D8がJPGの開始を表しており,既にPDF内のJPGが埋め込まれている部分を見ていることになります.
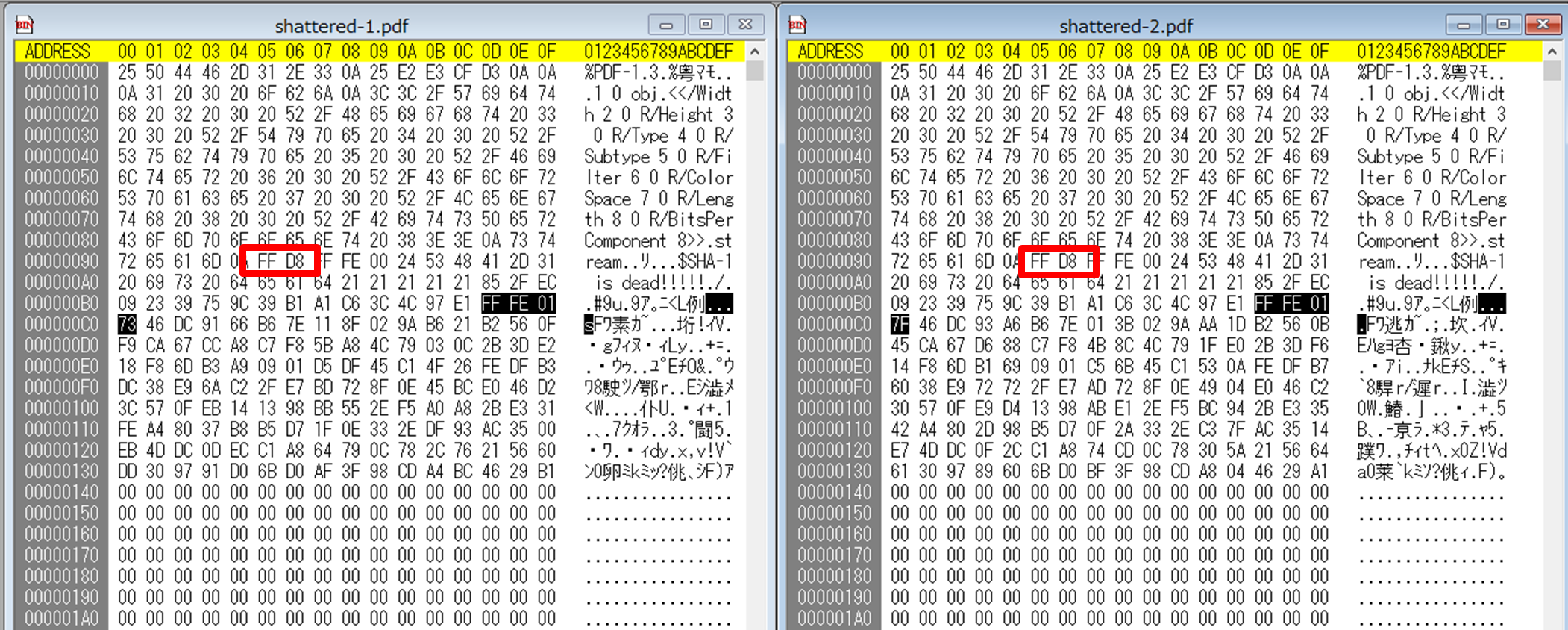
このようにJPGは開始していますが,まだ表示される赤と青のJPG画像は関係ありません.ここで大事なのは先ほど申し上げたJPG内のコメント部分です.
ここで,少しJPGファイルの構造について触れます.こちらのサイトでJPGのJFIF形式を見ていただけると参考になると思いますが,ここでは必要なものだけ説明します.以下がJFIF形式のフォーマットの一部になります.
- FF D8 -> JPGデータの開始
- FF D9 -> JPGデータの終了
- FF DA -> スキャン開始
- FF FE -> コメント
FF XXなどの値をマーカー値と呼びます.JFIF形式では,FF D8が開始を表し,FF D9が終了を表します.また,FF DA からが目に見える画像自体のデータの開始です (スキャン開始).これらのマーカー値は覚えておくとこの後の構造理解がしやすいです.またセグメント一覧の一番下を見ると,FF FEというマーカー値があり,コメントと書いてあるのが分かると思います.コメントの部分は画像データとはみなされず,任意の文字列を含めることが可能です.さて,FF FEの後にコメントが来るわけですが,どこまでがコメントなのでしょうか.それは,FF FEの直後の2バイトが表しています.FF FEの直後の2バイトの値から2を引いた分のコメントが続きます.つまり,shattered-1.pdfの方は0x173,つまり371から2を引いた369バイト分のコメントが続き,shattered-2.pdfの方は0x17f,つまり383から2を引いた381バイト分のコメントが続きます.
このコメントが衝突PDFに何の関係があるかと言いますと,このコメントの値が違うことでPDFに表示される画像が変化しているのです.
衝突PDFの構造を考える
言葉で説明しにくいので百聞は一見に如かずなので,以下に衝突PDFの仕掛けを図示します.左右二つに分かれた四角は各PDFの16進バイナリだと思ってください.
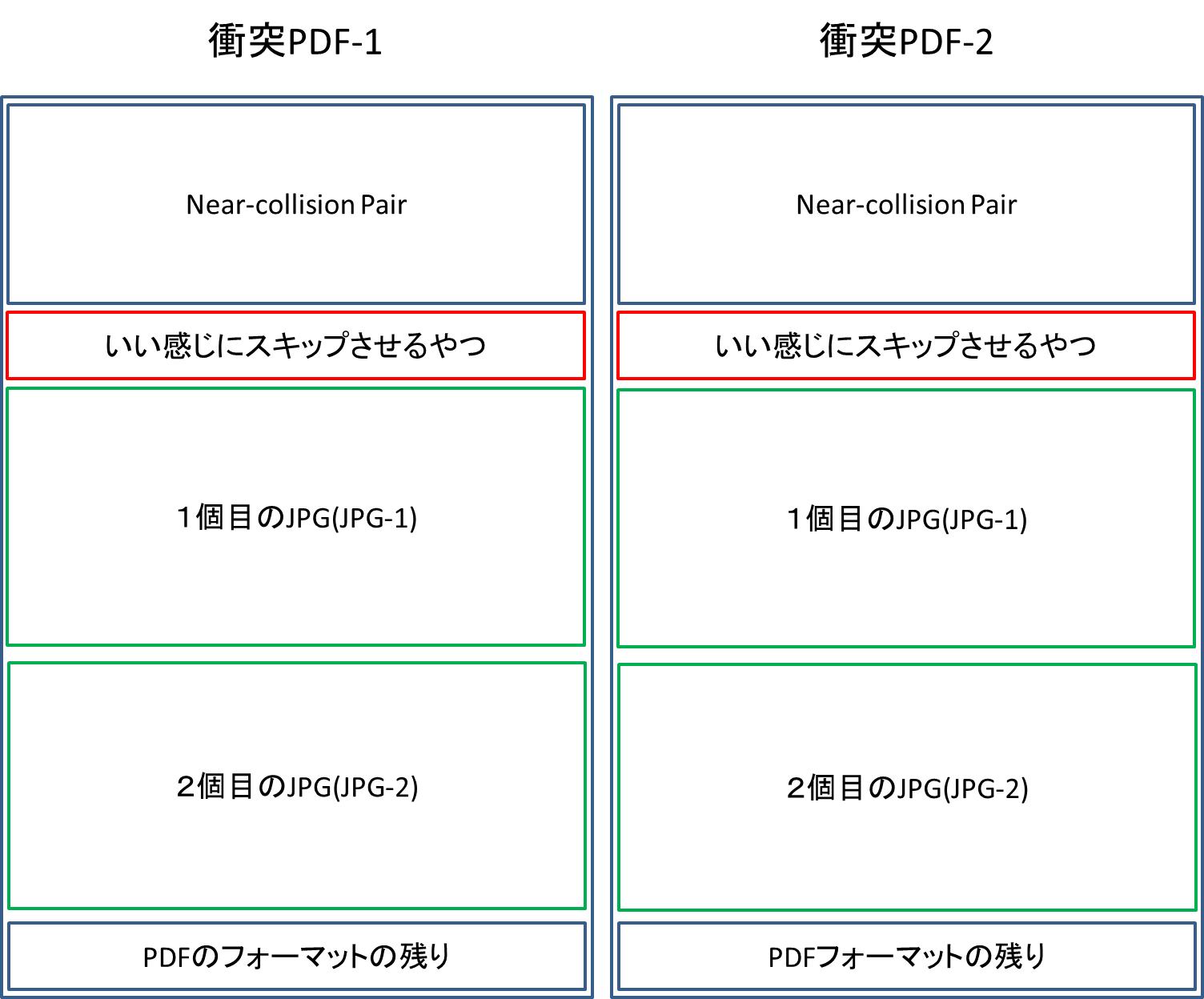
構造的にはこんな感じです.各ブロックには16進バイナリが入ります.また,Near-collision Pair以下は全く同じで,全く同じ16進が並びます.
この構造の元,以下のようにバイナリを組み立てます.
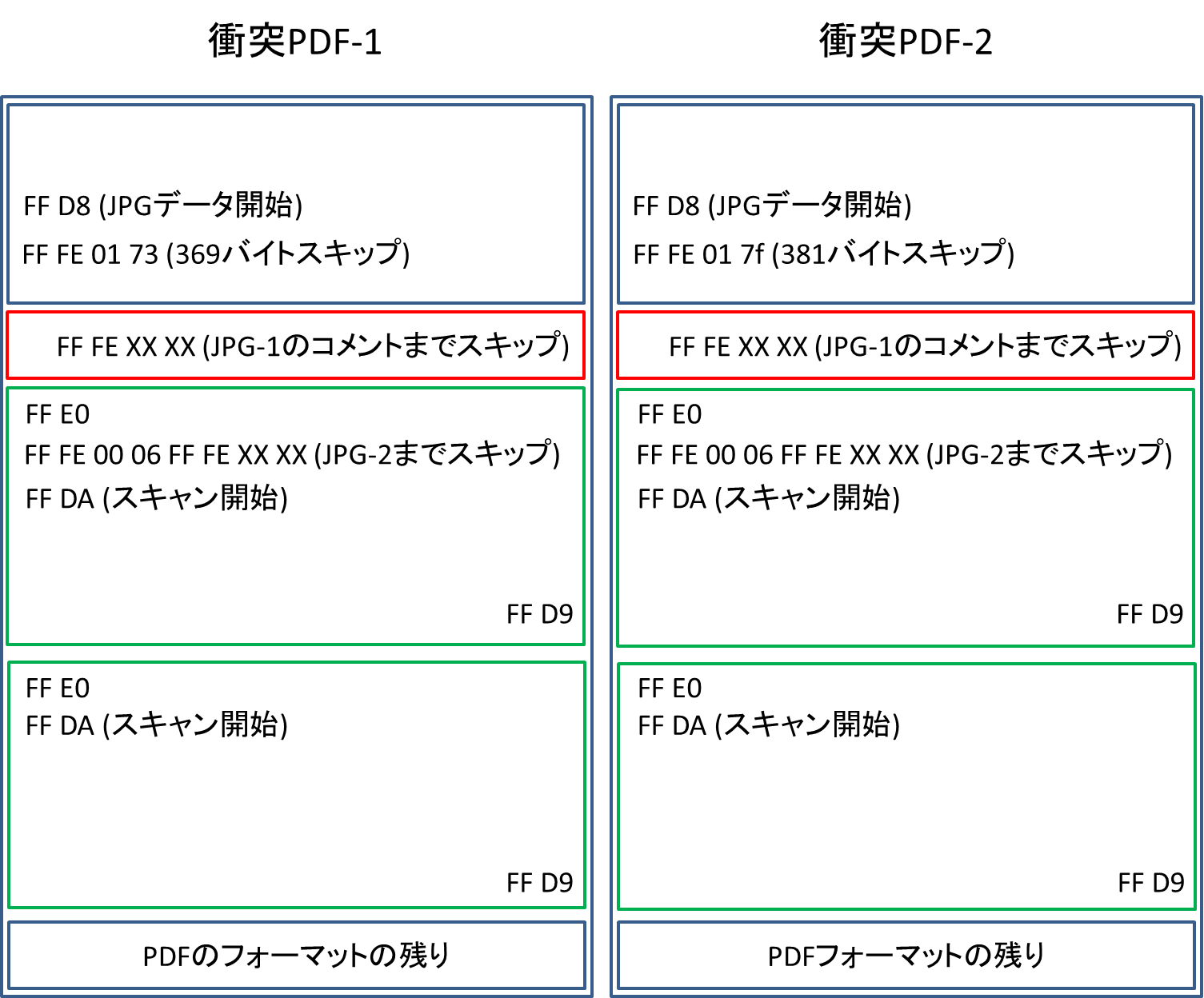
赤い部分で,各JPGをスキップするようにコメントの範囲を設定すると,以下のようにデータがスキップされます.
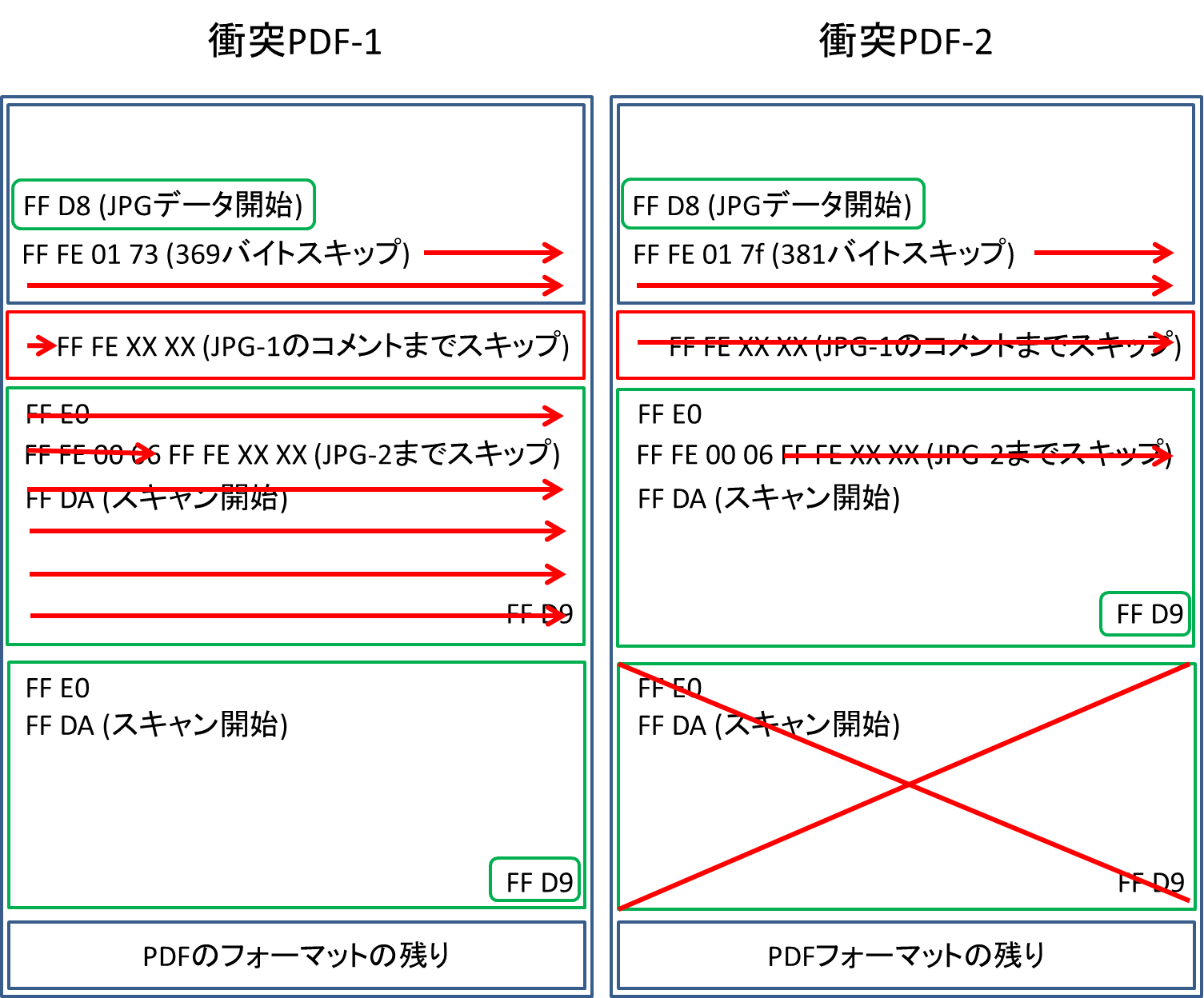
衝突PDF1では,最初のスキップで369バイトしかスキップしないので,一つ目の赤いブロックのコメントを読み込むことができます.すると,JPG-1のコメント部分までスキップします.ここで,FF FE 00 06も飛ばしてFF FE XX XXまでいくようにコメント範囲を設定しておきます.さらにFF FE XX XXの部分でJPG-2までスキップするようにコメント範囲を設定しておけば,JPG-2のみが正常に読み込まれます.そうすると,衝突PDF1ではJPG-2の方が表示されることになります.
一方,衝突PDF2では,最初のスキップで381バイトスキップして,一つ目の赤いブロックもスキップしてJPG-1までいけます.JPG-1を正常に読み込んだ時,読み込むコメントはFF FE 00 06となります.これは4バイトをコメントとみなすということになるので,「JPG-2までスキップするコメント(FF FE XX XXの部分)」をスキップすることができ,JPG-1のFF DA以降も正常に読み込めます.そのようにJPG-1を正常に読み込んだ後は,既に画像データがきちんと終了しているので,次の画像データであるJPG-2が読み込まれて表示されることはありません.これはおそらく仕様だと思っています.仕様周りは分かり次第書き直します.
そして,最後は双方共にPDFの残りのフォーマットを読み込むのできちんとPDFを作ることが可能です.
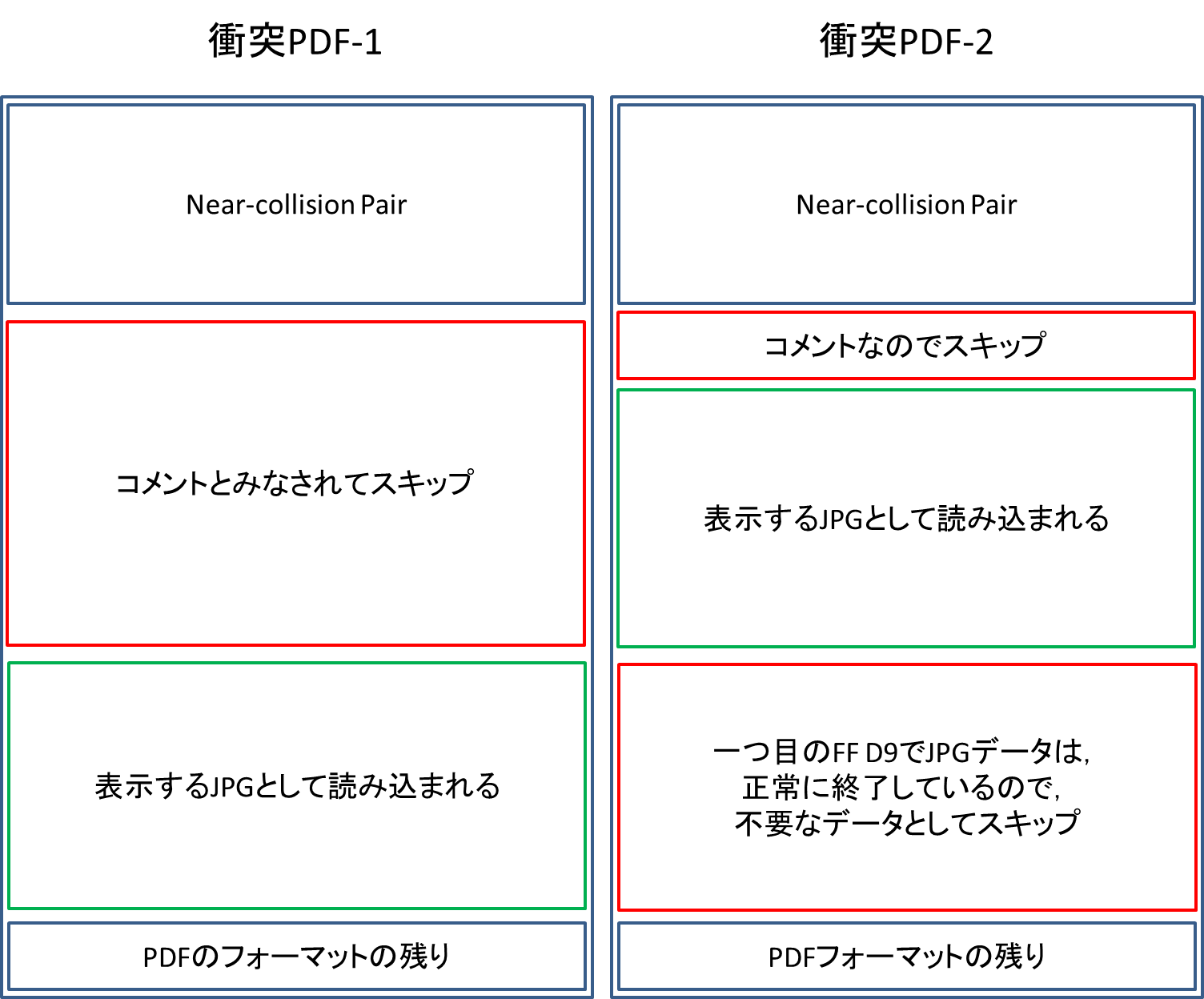
このような構造を作ることができれば,衝突PDFを作ることが可能です.正確には,コメントは上だけでは不十分なこともあります.例えば,画像データが大きくてFF DA(スキャン開始)が何度も出てくる場合は,一度のスキップではスキップしきれないことがあるので,FF DAごとにコメントをつけてスキップさせる必要があります.その場合はFF DAの前にコメントを入れます.また,PDFフォーマットも画像の大きさ等によって書き換える必要があります.
自分で衝突PDFを作ってみる
衝突PDFを作るにあたって必要なものは以下になります.
- バイナリエディタ (stirlingとか)
- 衝突PDFの片方に表示させるJPG-1 (既存のものと同じサイズだと楽)
- 衝突PDFのもう片方に表示させるJPG-2 (既存のものと同じサイズだと楽)
- Near-collision Pair
- Near-collision Pairの後に付けるコメント (図の一つ目の赤いブロック)
- 末尾に付加するPDFのフォーマット
このうち,最低限細工が必要なのはJPG-1と先頭320バイト+αです.これらを上の図のように上手いこと相互のJGPをスキップするよう細工して作ったPDFが以下になります.
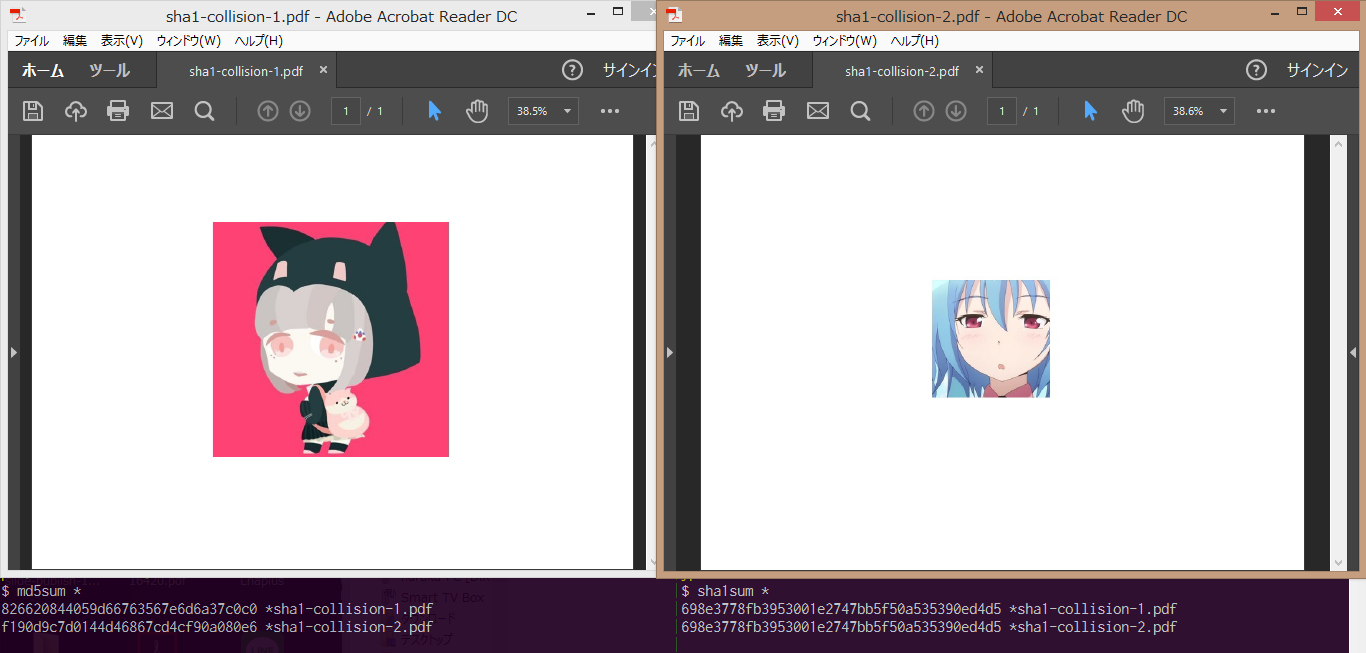
このように,md5が異なる別々のファイルにも拘わらず,SHA-1が同じになっていることが分かります.
制限
以下,私ができていない部分になります.
- 一部の画像では衝突PDFが作れない
- 正確にはPDFフォーマットに準拠していない
一つ目については,コメントで飛ばすことができないデータ構造のJPGが使えないということです.コメントはFF FE XX XXのXの部分2バイトできまるので,この範囲を超える場合はどうすれば良いのかが分かっていません...(色々試したり調べたのですが...)
二つ目はPDFフォーマットに準拠していない点です.PDFフォーマットが異なるとブラウザでは表示できますがAdobeのリーダー等ではきちんと表示されません.例えば以下のスクリプトでつくった衝突PDFはブラウザでは表示されますがAdobeでは表示されません.
上図では既存の衝突PDFに使われていたJPGと同じ大きさのJPGを用意したので,Adobeのリーダーで上手く表示されますが,そうでない場合PDFフォーマットを書き換える必要があります.ですが今回はそこまでできていません.もちろんできた方が良いですが,今回はSHA-1衝突の原理の理解が目的だったのでそこまでしなくて良いと考え,ここまでにしました.こちらのsonickunという方がPDFフォーマット準拠については行っているので,そちらを参考にするとよいと思います.
まとめ
GoogleがIdentifical-prefix Collision Attackによって発見したNear-collision Pairを使うことによって,簡単にSHA-1衝突PDFを作ることができます.衝突PDFはJPG仕様であるコメントを細工することによって作ることが可能です.興味のある人は是非やってみてください.
参考